by Ivan Skytte Jørgensen, January 2012
There are many excellent guides and howto's on linux firewalling and routing. But over the years my setup has grown to include som features that by themselves are easy to configure but not-so-easy to integrate into an existing setup, and I have frequently encountered areas where the guides and manuals are incomplete or out of date. I hope this document will help fellow networking-interested people.
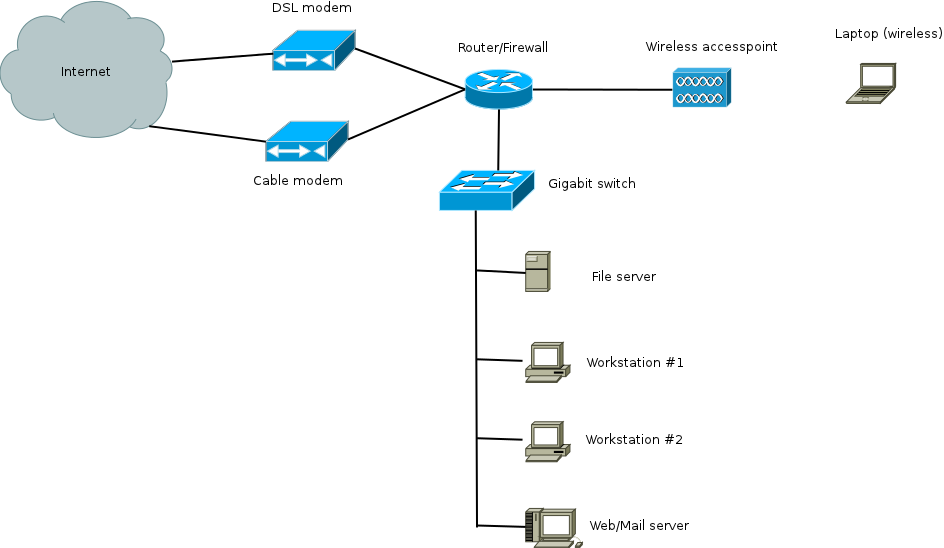
This document describes my network setup at home which features:
The physical setup consists of:
Most of this document will focus on the configuration of the Soekris box.
The soekris ports are used as follows:
| Port | Used for | (net) |
|---|---|---|
| eth0 | Internal LAN, connected to the switch | 10.0.0.20/24 |
| eth1 | xDSL modem | |
| eth2 | dead (a previous xDSL modem burned it out) | |
| eth3 | internal network infrequently used | 10.0.4.1/24 |
| eth4 | cable modem | |
| eth5 | down (IRQ conflict) | |
| eth6 | Wireless (with VLAN tagging. See later) | 10.0.6.1/24 |
| eth7 | down (IRQ conflict) |
Networks:
| 10.0.0.0/24 | Internal LAN, all hosts are trusted |
| 10.0.4.0/24 | Internal LAN (single cable), all hosts are trusted |
| 10.0.6.0/24 | Management LAN to wireless access point |
| 10.0.60.0/24 | Wireless network. Potentially hostile hosts |
| 10.0.61.0/24 | Wireless guest network. Potentially hostile hosts |
The nice access point supports multiple SSIDs and VLAN tagging, as well as dual-band radio frequencies. Since I wanted to provide guests with easy access I made a SSID for that and told the AP put them on VLAN 61. The other 5GHz-only network I use for my laptop, and I configured the AP to put that SSID on VLAN 60.
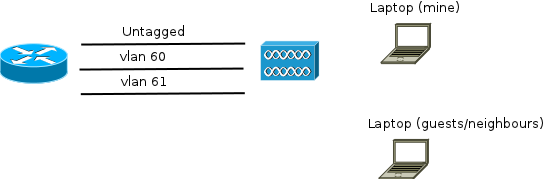
On the soekris I used the OpenSuSE "yast" tool to configure the VLAN. It was really easy. This is the resulting configuration files:
# cat /etc/sysconfig/network/ifcfg-vlan60
BOOTPROTO='static' BROADCAST='' ETHERDEVICE='eth6' ETHTOOL_OPTIONS='' IPADDR='10.0.60.1/24' MTU='' NAME='' NETWORK='' REMOTE_IPADDR='' STARTMODE='onboot' USERCONTROL='no' PREFIXLEN='24'
# cat /etc/sysconfig/network/ifcfg-vlan61
BOOTPROTO='static' BROADCAST='' ETHERDEVICE='eth6' ETHTOOL_OPTIONS='' IPADDR='10.0.61.1/24' MTU='' NAME='' NETWORK='' REMOTE_IPADDR='' STARTMODE='onboot' USERCONTROL='no' PREFIXLEN='24'
For firewall I use manually configured iptables. I did consider using one of the many nice GUI tools to do it but I assumed that I would quickly run into special rules that the GUI wouldn't support. I was probably right. The script is put into /etc/rc.d/
The start of the script flushes all rules, loads the needed support modules, and sets a conservative default policy:
#probe modprobe ip_tables modprobe iptable_nat # Initialize by flushing all tables iptables --flush iptables -t nat --flush iptables -t mangle --flush # Flush user-defined tables iptables --delete-chain iptables -t nat --delete-chain iptables -t mangle --delete-chain # ------------------ # Set default policy iptables --policy INPUT DROP iptables --policy OUTPUT ACCEPT iptables --policy FORWARD DROP iptables -t nat --policy PREROUTING ACCEPT iptables -t nat --policy POSTROUTING ACCEPT iptables -t nat --policy OUTPUT ACCEPT # loopback interface is essential and safe iptables -A INPUT -i lo -j ACCEPT iptables -A OUTPUT -o lo -j ACCEPT
Some iptables guides recommend to also set the default policy for OUTPUT to DROP. They need to have their heads examined. This is the firewall. If you cannot trust packets originating from the firewall itself then you have a serious problem.
The script also stops incorrect IP-addresses from being used:
#reject private-network-ipaddresses that we don't use iptables -A FORWARD -d 172.16.0.0/12 -j REJECT --reject-with icmp-net-unreachable iptables -A FORWARD -d 192.168.0.0/16 -j REJECT --reject-with icmp-net-unreachable #...and spoofed/misconfigured ip-address iptables -A FORWARD -s 172.16.0.0/12 -j DROP iptables -A FORWARD -s 192.168.0.0/16 -j DROP iptables -A FORWARD -s 10.0.0.0/8 -i eth1 -j DROP iptables -A FORWARD -s 10.0.0.0/8 -i eth4 -j DROP
In my network I don't use the 172.16 and the 192.168 networks, so everything to those networks are dropped.
The reason for the last two rules is that if someone managed to hack one of the ISPs' routers and send packets with a 10.*.*.* address to my system then the firewall would otherwise happily forward them and potentially treat them with more trust because 10.*.*.* is normally an internal network. The last two rules prevent that. IP-addresses that I do use are explicitly enabled based on the port they arrive on. Additionally, eth4 (cable) is essentially a broadcast medium and if someone has a flaky cable modem then 10.x.x.x packets can arrive on eth4. For the past 4 months the counters are:
# iptables -vn -L FORWARD|fgrep DROP|fgrep 10.0.0.0/8
0 0 DROP all -- eth1 * 10.0.0.0/8 0.0.0.0/0
46 3157 DROP all -- eth4 * 10.0.0.0/8 0.0.0.0/0
The iptables script then allows specific services that run on the firewall itself. Because I have multiple untrusted wireless networks I made a chain for that:
#Chain for local services on a wifi port iptables -N wifiinput iptables -A wifiinput -p icmp -j out_icmp #allow icmp, but filter #allow only a few select services iptables -A wifiinput -p tcp --dport 22 -j ACCEPT #SSH iptables -A wifiinput -p udp --dport 546 -j ACCEPT #DHCPv6 Client iptables -A wifiinput -p tcp --dport 546 -j ACCEPT #DHCPv6 Client iptables -A wifiinput -p udp --dport 547 -j ACCEPT #DHCPv6 Server iptables -A wifiinput -p tcp --dport 547 -j ACCEPT #DHCPv6 Server iptables -A wifiinput -p udp --dport 67 -j ACCEPT #bootp server iptables -A wifiinput -p tcp --dport 67 -j ACCEPT #bootp server iptables -A wifiinput -p udp --dport 514 -j ACCEPT --match limit --limit 120/minute #syslog(udp) from access point iptables -A wifiinput -p udp --dport 514 -j DROP #allow us to configure the access point with telnet/ssh iptables -A wifiinput -p tcp --sport 23 -m state --state ESTABLISHED -j ACCEPT iptables -A wifiinput -p tcp --sport 22 -m state --state ESTABLISHED -j ACCEPT #reject everything else iptables -A wifiinput -p udp -j REJECT --reject-with icmp-port-unreachable iptables -A wifiinput -p tcp -j REJECT --reject-with icmp-port-unreachable #By default, drop everything iptables -A wifiinput -m limit -j LOG --log-prefix "wifiinput " iptables -A wifiinput -j REJECT
...and then refer to that in the rule setup for the wireless ports:
... #vlan60 - untrusted wireless lan iptables -A INPUT -i vlan60 -j wifiinput ... #vlan61 - untrusted wireless lan iptables -A INPUT -i vlan61 -j wifiinput
Some of the services run on internal servers so I made a chain for that too:
#A chain to allow internal services (non-local on eth0) iptables -N wififwdsvc iptables -A wififwdsvc -d 10.0.0.11 -p tcp --dport 80 -j ACCEPT #http iptables -A wififwdsvc -d 10.0.0.11 -p udp --dport 53 -j ACCEPT #DNS is OK iptables -A wififwdsvc -d 10.0.0.11 -p tcp --dport 53 -j ACCEPT #DNS is OK iptables -A wififwdsvc -d 10.0.0.11 -p udp --dport 123 -j ACCEPT #NTP is OK iptables -A wififwdsvc -d 10.0.0.11 -p tcp --dport 993 -j ACCEPT #imaps is OK iptables -A wififwdsvc -d 10.0.0.11 -p tcp --dport 25 -j ACCEPT #smtp is OK (server rejects relaying) iptables -A wififwdsvc -d 10.0.0.11 -p tcp --dport 22 -j ACCEPT #SSH iptables -A wififwdsvc -d 10.0.0.7 -p tcp --dport 22 -j ACCEPT #SSH iptables -A wififwdsvc -d 10.0.0.7 -p tcp --dport 3128 -j ACCEPT #transparent proxy iptables -A wififwdsvc -j RETURN
...and refer to that in the in the rule setup for the wireless ports:
... iptables -A FORWARD -i vlan60 -j wififwdsvc ... iptables -A FORWARD -i vlan61 -j wififwdsvc
The firewall also allows access from the internet to my web server, mail server, (and a few other things irrelevant to this document). For port eth1 and eth4 I set up:
#ssh to isjsys5 iptables -t nat -A PREROUTING -i eth1 -p tcp --dport 22 -j DNAT --to 10.0.0.11:22 iptables -t nat -A PREROUTING -i eth4 -p tcp --dport 22 -j DNAT --to 10.0.0.11:22 #smtp to isjsys5 iptables -t nat -A PREROUTING -i eth1 -p tcp --dport 25 -j DNAT --to 10.0.0.11:25 iptables -t nat -A PREROUTING -i eth4 -p tcp --dport 25 -j DNAT --to 10.0.0.11:25 #dns to isjsys5 iptables -t nat -A PREROUTING -i eth1 -p udp --dport 53 -j DNAT --to 10.0.0.11:53 iptables -t nat -A PREROUTING -i eth1 -p tcp --dport 53 -j DNAT --to 10.0.0.11:53 iptables -t nat -A PREROUTING -i eth4 -p udp --dport 53 -j DNAT --to 10.0.0.11:53 iptables -t nat -A PREROUTING -i eth4 -p tcp --dport 53 -j DNAT --to 10.0.0.11:53 ... #allow services running on isjsys5 iptables -A FORWARD -i eth1 -d 10.0.0.11 -p tcp --dport 22 -j filter_ssh iptables -A FORWARD -i eth1 -d 10.0.0.11 -p tcp --dport 22 -j ACCEPT #ssh iptables -A FORWARD -i eth1 -d 10.0.0.11 -p tcp --dport 25 -j ACCEPT #smtp iptables -A FORWARD -i eth1 -d 10.0.0.11 -p tcp --dport 53 -j ACCEPT #dns iptables -A FORWARD -i eth1 -d 10.0.0.11 -p udp --dport 53 -j ACCEPT #dns iptables -A FORWARD -i eth1 -d 10.0.0.11 -p tcp --dport 80 -j ACCEPT #http iptables -A FORWARD -i eth1 -d 10.0.0.11 -p tcp --dport 123 -j ACCEPT #ntp iptables -A FORWARD -i eth1 -d 10.0.0.11 -p udp --dport 123 -j ACCEPT #ntp ...
The PREROUTING DNAT rules maps incoming requests to the proper internal server, but I also have to explicitly allow them through the filter
The filter_ssh chain? I use that to filter out the blantant hacking attempts:
# A chain to filter ssh intrusion attempts iptables -N filter_ssh iptables -A filter_ssh -s 193.227.0.0/16 -j REJECT --reject-with icmp-host-prohibited #Supreme Council of Universities iptables -A filter_ssh -s 210.219.0.0/16 -j REJECT --reject-with icmp-host-prohibited #Korea Network Information Center iptables -A filter_ssh -s 203.190.128.0/19 -j REJECT --reject-with icmp-host-prohibited #Software Technology Parks of India,Block-IV iptables -A filter_ssh -s 211.157.98.25/10 -j REJECT --reject-with icmp-host-prohibited #Haidian District, Beijing iptables -A filter_ssh -s 122.200.64.0/18 -j REJECT --reject-with icmp-host-prohibited #Beijing HeJu ShuZi Telecom Engineering Co.Ltd. iptables -A filter_ssh -s 190.66.0.0/15 -j REJECT --reject-with icmp-host-prohibited #COLOMBIA TELECOMUNICACIONES S.A. ESP iptables -A filter_ssh -s 202.106.0.0/16 -j REJECT --reject-with icmp-host-prohibited #CNCGROUP Beijing province network iptables -A filter_ssh -s 219.151.0.0/13 -j REJECT --reject-with icmp-host-prohibited #CHINANET Guizhou province network ...
You get the idea :-).
Some of you might ask why I simply don't run the SSH service on a different port, or only allow connections from explicitly allowed networks. The reasons are that I sometimes travel for my work so I don't know where I might need remote access from; and since I use SSH public-keys there is no real danger in allowing the intrusion attemps and I get to know where there are insecure networks. If you use the same rules then I suggest that you sometimes look at the sshd log and check where the attempts come from by using the online whois lookup tools from ARIN, RIPE, APNIC and LACNIC. Depending on what I find I send an email to their abuse email address. In my experience hosting providers take reports very seriously. Universities and cable operators not so much.
The soekris acts as a DHCP server for the clients on the internal networks. The /etc/dhcpd.conf looks like this:
option domain-name "int.i1.dk";
option domain-name-servers 10.0.0.11;
include "/etc/named.keys";
#internal trusted network
subnet 10.0.0.0 netmask 255.255.255.0 {
range 10.0.0.6 10.0.0.254;
option domain-name-servers 10.0.0.11;
option domain-name "int.i1.dk";
option routers 10.0.0.20;
option broadcast-address 10.0.0.255;
option ntp-servers 10.0.0.11;
default-lease-time 600;
max-lease-time 7200;
}
...
#untrusted (wireless) network
subnet 10.0.60.0 netmask 255.255.255.0 {
range 10.0.60.4 10.0.60.254;
option domain-name-servers 10.0.0.11;
option domain-name "wifi.i1.dk";
option routers 10.0.60.1;
option broadcast-address 10.0.60.255;
option ntp-servers 10.0.0.11;
default-lease-time 600;
max-lease-time 7200;
zone wifi.i1.dk. { primary 10.0.0.11; key DHCP_UPDATER; }
zone 60.0.10.in-addr.arpa. { primary 10.0.0.11; key DHCP_UPDATER; }
}
host isjsys4vlan {
hardware ethernet 00:13:02:16:5d:55;
fixed-address 10.0.60.3;
option domain-name-servers 10.0.0.11;
option domain-name "wifi.i1.dk";
option routers 10.0.60.1;
option broadcast-address 10.0.2.255;
option ntp-servers 10.0.0.11;
default-lease-time 600;
max-lease-time 7200;
zone wifi.i1.dk. { primary 10.0.0.11; key DHCP_UPDATER; }
zone 60.0.10.in-addr.arpa. { primary 10.0.0.11; key DHCP_UPDATER; }
}
...
And /etc/named.keys looks something like this (note: not the actual key)
# generated by genDDNSkey on Mon Apr 24 23:42:32 CEST 2006
key DHCP_UPDATER {
algorithm hmac-md5;
secret "QuQTaGwPvdIocntCQjvSeJQmVDskdi4eksj7L1yQRwkKl23FoMms0I0IsxhozKpU+ayfaQOWP6yBHS5AMWjb/w==";
};
I just followed the ISC dhcpd manual. The only 2 non-standard things are:
$ fgrep DHCPD_INTERFACE /etc/sysconfig/dhcpd
DHCPD_INTERFACE="eth0 eth3 vlan60 vlan61"
Remember that key DHCP_UPDATER stuff in the dhcpd.conf configuration? That is used updating the internal DNS zones with the client names when they get an IP-address.
root@isjsys5# more /etc/named.conf
key DHCP_UPDATER
{
algorithm hmac-md5;
secret "QuQTaGwPvdIocntCQjvSeJQmVDskdi4eksj7L1yQRwkKl23FoMms0I0IsxhozKpU+ayfaQOWP6yBHS5AMWjb/w==";
};
...
zone "wifi.i1.dk" IN {
type master;
file "wifi.i1.dk.zone";
allow-update { key DHCP_UPDATER; };
check-names ignore; //people enter cr*p in they hostnames
};
Note: the key above is not the actual key. I'm not stupid enough to post that on the internet.
I haven't included all of the DNS configuration and zones. There is plenty of information and examples in the BIND manual. Besides, there is also a very good book on the subject, "DNS and Bind"
If you have read the other guides for transparent proxies then you probably ended up very confused. I made it simpler by:
The relevant iptables rules are:
#transparent proxy iptables -t nat -A PREROUTING -i eth0 -s ! 10.0.0.7 -p tcp --dport 80 -j DNAT --to 10.0.0.7:3128 iptables -t nat -A PREROUTING -i eth3 -p tcp --dport 80 -j DNAT --to 10.0.0.7:3128 iptables -t nat -A PREROUTING -i vlan60 -p tcp --dport 80 -j DNAT --to 10.0.0.7:3128 iptables -t nat -A PREROUTING -i vlan61 -p tcp --dport 80 -j DNAT --to 10.0.0.7:3128 iptables -t nat -A POSTROUTING -o eth0 -d 10.0.0.7 -p tcp --dport 3128 -j SNAT --to 10.0.0.20
So any HTTP traffic from the internal networks (except the proxy itself) get redirected to the proxy
The important configuration of the proxy (squid 3.1.11) is:
root@fileserver# more /etc/squid/squid.conf
... http_port 3128 transparent ...
Pay attention to the localnet ACL. By default it would allow untrusted wireless clients to connect to any internal server. After having given it much thought I allowed such access provided it uses a safe port. It keeps the configuration simpler and none of my machines run unsafe services on port 80.
The only thing not working is that squid tries to retrieve the original destination IP address but fails because it is not running as root. One day I will squelch that warning log line...
From my laptop I want to access my file server directly. Previously I used sshfs (filesystem-over-SSH) but it was quite slow. Instead I now use NFS directly. But NFS is a very insecure protocol (It can be made secure by using NFSv4, and authentication, and tokens, and, and ....).
I chose to use IPsec instead.
IPsec allows my laptop to talk directly to the fileserver and I don't have to worry about the NFS server using a dynamic port and reconfiguring the firewall to allow that, etc. IPsec setup is tricky, though. I could either use a dynamic IPsec association with key exchange and so on. Because I only needed one IPsec association and I control all of the network I opted for static keys
#allow ipsec from 10.0.60.3 (laptop) to fileserver iptables -A FORWARD -i vlan60 -d 10.0.0.7 -s 10.0.60.3 -p ah -j ACCEPT(traffic in the other direction is allowed because everything from eth0 is allowed)
#!/usr/sbin/setkey -f
# Flush the SAD and SPD
flush;
spdflush;
# AH SAs using 128 bit long keys
add 10.0.0.7 10.0.60.3 ah 0x200 -A hmac-md5 0x41c37a261c711f90ab100b420e2ad410;
add 10.0.60.3 10.0.0.7 ah 0x300 -A hmac-md5 0xd7b73fd38271f4409386d81e3af9d3a7;
# ESP SAs using 192 bit long keys (168 + 24 parity)
add 10.0.0.7 10.0.60.3 esp 0x201 -E 3des-cbc 0xf96d147f80f841538b6125971fc527b3e4cbda668a57e5e4;
add 10.0.60.3 10.0.0.7 esp 0x301 -E 3des-cbc 0xf593cb486da6d56be928defb33fd914486ee16f2804dd968;
# Security policies
spdadd 10.0.0.7 10.0.60.3 any -P out ipsec
esp/transport//require
ah/transport//require;
spdadd 10.0.60.3 10.0.0.7 any -P in ipsec
esp/transport//require
ah/transport//require;
The script is put into /etc/rc.d/
I have two ISP connections of roughly equal capacity. I want to have connections from the outside to balance over the two connections, and I want connections from the inside to balance over the two connections too.
There are almost-complete guides online that describe how to do that. It can be done in two ways:
I chose to use the latter option because it seemed more stable, and I need extra rules regarding outbound SMTP, ...
Every 10 minutes the soekris box checks the connectivity over the two ISP links. It is not enough to just ping the xdsl/cable modems because (a) they are bridges and can cannot be pinged, and (b) I don't care if the modem is working - I need to know if the upstream connection works
So for each of the ISP connections I have determined the first pingable router where traffic starts to fan out. I have then made a script that runs from cron and essentially does:
ping -c 1 -I eth1 <some-upstream-router> ping -c 1 -I eth4 <some-upstream-router>
and checks the result. If the ping failed it tries 5 times more before it deems the link defunct. It does that for both of the links. It sets the variables IF1ISUP and IF4ISUP accordingly.
If both links are working then it fixes the default route to eth1. After I configured load-balancing this is not really needed, but it does provide a fail-safe if the load-balancing fails or iptables are completely unloaded
If one link is working then it fixes the default router to point to that
It then configures policy-based routing:
...
#Now special rules so that we respond from the right interface and load-balance
ip rule del fwmark 1 2>/dev/null
ip rule del fwmark 1 iif eth0 2>/dev/null
ip rule del fwmark 1 iif vlan60 2>/dev/null
ip rule del fwmark 1 iif vlan61 2>/dev/null
ip rule del fwmark 4 2>/dev/null
ip rule del fwmark 4 iif eth0 2>/dev/null
ip rule del fwmark 4 iif vlan60 2>/dev/null
ip rule del fwmark 4 iif vlan61 2>/dev/null
if [ "$IF1ISUP" = "yes" ]; then
IP1=`cat /var/lib/dhcpcd/dhcpcd-eth1.info|grep '^IPADDR='|cut -d= -f2 |tr -d "'"`
if [ -n "$IP1" ]; then
VIA1=`cat /var/lib/dhcpcd/dhcpcd-eth1.info|grep '^GATEWAY='|cut -d= -f2`
[ -z "$VIA1" ] && VIA1=`cat /var/lib/dhcpcd/dhcpcd-eth1.info|grep '^GATEWAYS='|cut -d= -f2 |tr -d "'"`
ip route flush table 20
ip route add table 20 default via $VIA1 dev eth1
ip rule del unicast from $IP1
ip rule add unicast from $IP1 table 20 priority 504
ip rule add fwmark 1 priority 600 iif eth0 table 20 #load balancing rule
ip rule add fwmark 1 priority 600 iif eth3 table 20 #load balancing rule
ip rule add fwmark 1 priority 600 iif vlan60 table 20 #load balancing rule
ip rule add fwmark 1 priority 600 iif vlan61 table 20 #load balancing rule
fi
fi
if [ "$IF4ISUP" = "yes" ]; then
IP4=`cat /var/lib/dhcpcd/dhcpcd-eth4.info|grep '^IPADDR='|cut -d= -f2 |tr -d "'"`
if [ -n "$IP4" ]; then
VIA4=`cat /var/lib/dhcpcd/dhcpcd-eth4.info|grep '^GATEWAY='|cut -d= -f2`
[ -z "$VIA4" ] && VIA4=`cat /var/lib/dhcpcd/dhcpcd-eth4.info|grep '^GATEWAYS='|cut -d= -f2 |tr -d "'"`
ip route flush table 40
ip route add table 40 default via $VIA4 dev eth4
ip rule del unicast from $IP4
ip rule add unicast from $IP4 table 40 priority 504
ip rule add fwmark 4 priority 600 iif eth0 table 40 #load balancing rule
ip rule add fwmark 4 priority 600 iif eth3 table 40 #load balancing rule
ip rule add fwmark 4 priority 600 iif vlan60 table 40 #load balancing rule
ip rule add fwmark 4 priority 600 iif vlan61 table 40 #load balancing rule
fi
fi
What... what are all those rules doing? Explanation in next section
The script is not only called from the check-connectivity script. It also runs whenever eth1 or eth4 goes up. This is needed because:
$ fgrep -H POST_UP_SCRIPT /etc/sysconfig/network/ifcfg-*
/etc/sysconfig/network/ifcfg-eth1:POST_UP_SCRIPT='/root/eth1_post_up.sh' /etc/sysconfig/network/ifcfg-eth4:POST_UP_SCRIPT='/root/eth4_post_up.sh'Each of those scripts currently just call the fix-the-routes script.
Connections that have come in via eth1 must have all the associated packets routed out via eth1 too. Similar for eth4
I do this with iptables by marking new inbound connections with the interface they came in on
# Mark incoming connections to return on the interface they came in on iptables -t mangle -A PREROUTING -i eth1 -m state --state NEW -j CONNMARK --set-mark 1 iptables -t mangle -A PREROUTING -i eth4 -m state --state NEW -j CONNMARK --set-mark 4 ... iptables -t mangle -A PREROUTING -m state --state ESTABLISHED,RELATED -j CONNMARK --restore-mark
Example: When a new HTTP connection comes in on eth1, its connection-mark will be set to 1. It will then get routed normally and DNAT'ted and end up on my internal web server. When the response packet is received, the connection mark is restored to the packet mark. The packet then gets special treatment by the routing rules that match on fwmark 1 and will be routed out via eth1. It then goes through the usual iptables filters and gets de-DNAT'ted and eventually ends out on eth1
The actual load balancing is done by setting the external DNS entries with multiple IP-addresses. Eg:
$ nslookup -type=A i1.dk
Server: 10.0.0.11 Address: 10.0.0.11#53 Non-authoritative answer: Name: i1.dk Address: 83.89.100.6 Name: i1.dk Address: 188.176.48.94
So external clients will more-or-less randomly use external IP-addresses, and the load should be fairly even.
In case I make a mistake I also have these two rules:
iptables -A FORWARD -i eth1 -o eth4 -j DROP #don't forward between the two isps iptables -A FORWARD -i eth4 -o eth1 -j DROP #don't forward between the two isps
They have saved me a few times
When outbound connections are initiated they should use both upstream connections
While it is not real load-balancing, a simple round-robin setup using the statistic iptables module is adequate if the two upstream connections have roughly the same capacity (and it is easy to debug).
# Load balancing chain iptables -t mangle -N balance iptables -t mangle -A balance -d 10.0.0.0/8 -j RETURN iptables -t mangle -A balance -m connmark ! --mark 0 -j RETURN iptables -t mangle -A balance -m state --state ESTABLISHED,RELATED -j RETURN iptables -t mangle -A balance -m statistic --mode nth --every 2 --packet 0 -j CONNMARK --set-mark 1 iptables -t mangle -A balance -m statistic --mode nth --every 2 --packet 1 -j CONNMARK --set-mark 4 #failsafe: iptables -t mangle -A balance -m connmark --mark 0 -j CONNMARK --set-mark 4
Real load-balancing can be done using the rate estimators and iptables conditions. Because the capacity of the two links are not the same (14Mbs and 30Mbs) I instead use rule load-balancing.
#Rate estimators so we can do load-balancing iptables -t mangle -A PREROUTING -i eth1 -j RATEEST --rateest-name eth1_in --rateest-interval 250ms --rateest-ewma 0.5s iptables -t mangle -A PREROUTING -i eth4 -j RATEEST --rateest-name eth4_in --rateest-interval 250ms --rateest-ewma 0.5s iptables -t mangle -A POSTROUTING -o eth1 -j RATEEST --rateest-name eth1_out --rateest-interval 250ms --rateest-ewma 0.5s iptables -t mangle -A POSTROUTING -o eth4 -j RATEEST --rateest-name eth4_out --rateest-interval 250ms --rateest-ewma 0.5s # Load balancing chain iptables -t mangle -N balance iptables -t mangle -A balance -d 10.0.0.0/8 -j RETURN iptables -t mangle -A balance -m connmark ! --mark 0 -j RETURN iptables -t mangle -A balance -m state --state ESTABLISHED,RELATED -j RETURN iptables -t mangle -A balance -m rateest --rateest-delta --rateest1 eth1_in --rateest-bps1 14mbit --rateest-lt --rateest2 eth4_in --rateest-bps2 30mbit -j CONNMARK --set-mark 4 iptables -t mangle -A balance -m rateest --rateest-delta --rateest1 eth1_in --rateest-bps1 14mbit --rateest-gt --rateest2 eth4_in --rateest-bps2 30mbit -j CONNMARK --set-mark 1 #failsafe: iptables -t mangle -A balance -m connmark --mark 0 -j CONNMARK --set-mark 4
For both types of balancing the chain starts with 2 fail-safe rules. If the destination is an internal network or the connection isn't new then we should not try to direct the routing. The chain ends with another fail-safe. if the rules didn't set a routing mark the we default to 4
The balance chain is called from a routing chain:
#Routing chain for NEW outgoing connections
iptables -t mangle -N route
iptables -t mangle -A route -d 10.0.0.0/8 -j RETURN
iptables -t mangle -A route -m connmark ! --mark 0 -j RETURN
iptables -t mangle -A route -m state --state ESTABLISHED,RELATED -j RETURN
iptables -t mangle -A route -i eth0 -p tcp --dport 500 -j CONNMARK --set-mark 1 #old VPN client
iptables -t mangle -A route -i eth0 -p udp --dport 500 -j CONNMARK --set-mark 1 #old VPN client
iptables -t mangle -A route -i eth0 -p tcp --dport 4500 -j CONNMARK --set-mark 1 #old VPN client
iptables -t mangle -A route -i eth0 -p udp --dport 4500 -j CONNMARK --set-mark 1 #old VPN client
iptables -t mangle -A route -d 92.43.126.0/24 -j CONNMARK --set-mark 4 #yousee selfcare
iptables -t mangle -A route -d 194.239.10.114/24 -j CONNMARK --set-mark 4 #yousee selfcare
iptables -t mangle -A route -d 212.93.36.130/19 -j CONNMARK --set-mark 4 #danske bank
iptables -t mangle -A route -d 131.165.0.0/16 -j CONNMARK --set-mark 4 #kommunedata/nemid
iptables -t mangle -A route -d 213.174.69.0/20 -j CONNMARK --set-mark 4 #TDC hosting
for if in eth0 eth2 eth3 eth5 eth6 vlan60 vlan61 eth7; do
iptables -t mangle -A route -i $if -p tcp --dport 25 -j CONNMARK --set-mark 1
iptables -t mangle -A route -i $if -j balance
done
The route chain starts with two fail-safes: If the destination is an internal network or if something has already set the routing mark or if the connection isn't new then we do nothing.
The next 4 rules (the ones about port 500 and port 4500) are to accomodate an old IPSec client that cannot handle load-balancing, so I always route it via eth1
The next 2 rules ("yousee selfcare") are about the selfcare interface for the ISP on eth4. The selfcare is not completely functional if accessed from outside their net, so I always route that traffic via eth4
The next 3 rules (danske bank, kommunedata, tdc hosting) are necessary for my online banking. Apparently the authentication phase checks if the client IP changes, and aborts if it does. After some time tracking down which nets the online banking and sign-in application uses have fixed the routing to those net to always go out via the same interface
Then we come to the more interesting rules concerning the load-balancing:
For all the internal interfaces: if a new connection is initiated from that then the balance chain is called. the balance chain refuses to balance if the destination is the internal network (that way the ip routing fwmark rules don't match). If something has already marked the packet or if it isn't a new connection then it refuses too. Otherwise it balances outgoing connections evenly.
The only exception above is that SMTP must go out via eth1 because the other ISP blocks port 25.
The resulting ip rules are:
$ ip -4 rule show
0: from all lookup local 504: from 188.176.48.94 lookup force_eth1 504: from 83.89.100.6 lookup force_eth4 600: from all fwmark 0x1 iif eth0 lookup force_eth1 600: from all fwmark 0x1 iif eth3 lookup force_eth1 600: from all fwmark 0x1 iif vlan60 lookup force_eth1 600: from all fwmark 0x1 iif vlan61 lookup force_eth1 600: from all fwmark 0x4 iif eth0 lookup force_eth4 600: from all fwmark 0x4 iif eth3 lookup force_eth4 600: from all fwmark 0x4 iif vlan60 lookup force_eth4 600: from all fwmark 0x4 iif vlan61 lookup force_eth4 32766: from all lookup main 32767: from all lookup default
$ ip -4 route show table 20
default via 188.176.48.93 dev eth1
$ ip -4 route show table 40
default via 83.89.100.1 dev eth4
$ ip -4 route show table main
188.176.48.92/30 dev eth1 proto kernel scope link src 188.176.48.94 10.0.4.0/24 dev eth3 proto kernel scope link src 10.0.4.1 10.0.6.0/24 dev eth6 proto kernel scope link src 10.0.6.1 10.0.0.0/24 dev eth0 proto kernel scope link src 10.0.0.20 10.0.2.0/24 dev eth2 proto kernel scope link src 10.0.2.1 10.0.61.0/24 dev vlan61 proto kernel scope link src 10.0.61.1 10.0.60.0/24 dev vlan60 proto kernel scope link src 10.0.60.1 83.89.100.0/24 dev eth4 proto kernel scope link src 83.89.100.6 169.254.0.0/16 dev eth0 scope link 127.0.0.0/8 dev lo scope link default via 188.176.48.93 dev eth1 metric 1 default via 83.89.100.1 dev eth4 metric 2
The last two routes (default) are not normally used, but if there is an error in the iptables marking so an outbound packets goes unmarked then it hits a reasonable route.
Where did those "force_eth1" and "force_eth4" names come from? Answer:
soekris2:~ # cat /etc/iproute2/rt_tables
# # reserved values # 255 local 254 main 253 default 0 unspec # # local # #1 inr.ruhep 20 force_eth1 40 force_eth4
(Adding them to that file is entirely optional)
The nice thing about this setup is that iptables can be used for classifying the traffic and give a hint to the routing mechanism, but if one of the upstream links are down then the routing table will select the remaining working link regardless of the iptables fwmark.
Not all traffic is equally important. Eg:
With my current multi-ISP load-balancing setup it hasn't been much of a problem, so I currently don't shape traffic because it keeps the configuration simpler. But anyway, here we go:
The traffic class is determined by iptables
#mark packets so they can be shaped iptables -t mangle -A FORWARD -i eth1 -o vlan60 -d ! 10.0.60.3 -j MARK --set-mark 1 #dfl iptables -t mangle -A FORWARD -i eth1 -o vlan60 -d 10.0.60.3 -j MARK --set-mark 2 #root iptables -t mangle -A FORWARD -i eth4 -o vlan60 -d ! 10.0.60.3 -j MARK --set-mark 4 #dfl iptables -t mangle -A FORWARD -i eth4 -o vlan60 -d 10.0.60.3 -j MARK --set-mark 5 #root iptables -t mangle -A FORWARD -i eth1 -o vlan61 -d ! 10.0.60.3 -j MARK --set-mark 1 #dfl iptables -t mangle -A FORWARD -i eth1 -o vlan61 -d 10.0.60.3 -j MARK --set-mark 2 #root iptables -t mangle -A FORWARD -i eth4 -o vlan61 -d ! 10.0.60.3 -j MARK --set-mark 4 #dfl iptables -t mangle -A FORWARD -i eth4 -o vlan61 -d 10.0.60.3 -j MARK --set-mark 5 #root # iptables -t mangle -A FORWARD -i vlan60 -o eth1 -m mac --mac-source ! 00:13:02:16:5d:55 -j MARK --set-mark 1 #dfl iptables -t mangle -A FORWARD -i vlan60 -o eth1 -m mac --mac-source 00:13:02:16:5d:55 -j MARK --set-mark 2 #root iptables -t mangle -A FORWARD -i vlan60 -o eth1 -m mac --mac-source 00:16:CF:53:6C:83 -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan60 -o eth1 -m mac --mac-source 00:14:a4:48:b8:0e -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan60 -o eth1 -m mac --mac-source 00:1c:26:0d:2f:6e -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan61 -o eth1 -m mac --mac-source ! 00:13:02:16:5d:55 -j MARK --set-mark 1 #dfl iptables -t mangle -A FORWARD -i vlan61 -o eth1 -m mac --mac-source 00:13:02:16:5d:55 -j MARK --set-mark 2 #root iptables -t mangle -A FORWARD -i vlan61 -o eth1 -m mac --mac-source 00:16:CF:53:6C:83 -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan61 -o eth1 -m mac --mac-source 00:14:a4:48:b8:0e -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan61 -o eth1 -m mac --mac-source 00:1c:26:0d:2f:6e -j MARK --set-mark 3 #bwhogs # iptables -t mangle -A FORWARD -i vlan60 -o eth4 -m mac --mac-source ! 00:13:02:16:5d:55 -j MARK --set-mark 1 #dfl iptables -t mangle -A FORWARD -i vlan60 -o eth4 -m mac --mac-source 00:13:02:16:5d:55 -j MARK --set-mark 2 #root iptables -t mangle -A FORWARD -i vlan60 -o eth4 -m mac --mac-source 00:16:CF:53:6C:83 -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan60 -o eth4 -m mac --mac-source 00:14:a4:48:b8:0e -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan60 -o eth4 -m mac --mac-source 00:1c:26:0d:2f:6e -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan61 -o eth4 -m mac --mac-source ! 00:13:02:16:5d:55 -j MARK --set-mark 1 #dfl iptables -t mangle -A FORWARD -i vlan61 -o eth4 -m mac --mac-source 00:13:02:16:5d:55 -j MARK --set-mark 2 #root iptables -t mangle -A FORWARD -i vlan61 -o eth4 -m mac --mac-source 00:16:CF:53:6C:83 -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan61 -o eth4 -m mac --mac-source 00:14:a4:48:b8:0e -j MARK --set-mark 3 #bwhogs iptables -t mangle -A FORWARD -i vlan61 -o eth4 -m mac --mac-source 00:1c:26:0d:2f:6e -j MARK --set-mark 3 #bwhogs # iptables -t mangle -A FORWARD -i eth0 -o eth1 -p tcp --sport 80 -j MARK --set-mark 4 #http iptables -t mangle -A FORWARD -i eth0 -o eth4 -p tcp --sport 80 -j MARK --set-mark 4 #http # iptables -t mangle -A FORWARD -i eth0 -o vlan60 -d 10.0.60.3 -p ah -j MARK --set-mark 7 #nfs
So essentially iptables are used to set a fwmark on the packet according to which connection it came from and who/what is responsible for the traffic
The traffic is then shaped with tc HTB:
#First clear old setup tc qdisc del dev eth0 root handle 1:0 tc qdisc del dev eth1 root handle 1:0 tc qdisc del dev eth2 root handle 1:0 tc qdisc del dev eth4 root handle 1:0 tc qdisc del dev eth6 root handle 1:0 tc qdisc del dev vlan60 root handle 1:0 tc qdisc del dev vlan61 root handle 1:0 ### eth1 (xDSL 13.72mbit/1.69mbit) tc qdisc add dev eth1 root handle 1:0 htb default 10 tc class add dev eth1 parent 1:0 classid 1:1 htb rate 1700kbit tc class add dev eth1 parent 1:1 classid 1:10 htb rate 566kbit ceil 1500kbit #dfl tc class add dev eth1 parent 1:1 classid 1:11 htb rate 566kbit ceil 1700kbit #root tc class add dev eth1 parent 1:1 classid 1:12 htb rate 255kbit ceil 800kbit #bwhogs tc class add dev eth1 parent 1:1 classid 1:13 htb rate 256kbit ceil 1200kbit #http tc filter add dev eth1 protocol ip parent 1:0 prio 1 handle 1 fw classid 1:10 tc filter add dev eth1 protocol ip parent 1:0 prio 1 handle 2 fw classid 1:11 tc filter add dev eth1 protocol ip parent 1:0 prio 1 handle 3 fw classid 1:12 tc filter add dev eth1 protocol ip parent 1:0 prio 1 handle 4 fw classid 1:13 ### eth4 (cable 4mbit/512) tc qdisc add dev eth4 root handle 1:0 htb default 10 tc class add dev eth4 parent 1:0 classid 1:1 htb rate 512kbit tc class add dev eth4 parent 1:1 classid 1:10 htb rate 160kbit ceil 348kbit #dfl tc class add dev eth4 parent 1:1 classid 1:11 htb rate 160kbit ceil 512kbit #root tc class add dev eth4 parent 1:1 classid 1:12 htb rate 64kbit ceil 256kbit #bwhogs tc class add dev eth4 parent 1:1 classid 1:13 htb rate 128kbit ceil 256kbit #http tc filter add dev eth4 protocol ip parent 1:0 prio 1 handle 1 fw classid 1:10 tc filter add dev eth4 protocol ip parent 1:0 prio 1 handle 2 fw classid 1:11 tc filter add dev eth4 protocol ip parent 1:0 prio 1 handle 3 fw classid 1:12 tc filter add dev eth4 protocol ip parent 1:0 prio 1 handle 4 fw classid 1:13 ### eth6 (wireless 54mbit) #no shaping - tc filter appears to not handle 'fw' rules when packets are vlan-tagged ### vlan60 (wireless 54mbit) tc qdisc add dev vlan60 root handle 1:0 htb default 10 tc class add dev vlan60 parent 1:0 classid 1:1 htb rate 54mbit tc class add dev vlan60 parent 1:1 classid 1:10 htb rate 1mbit ceil 12000kbit #dfl tc class add dev vlan60 parent 1:1 classid 1:11 htb rate 1mbit ceil 20000kbit #root tc class add dev vlan60 parent 1:1 classid 1:12 htb rate 1mbit ceil 10000kbit #bwhogs tc class add dev vlan60 parent 1:1 classid 1:13 htb rate 2mbit ceil 3500kbit #dfl tc class add dev vlan60 parent 1:1 classid 1:14 htb rate 2mbit ceil 8000kbit #root tc class add dev vlan60 parent 1:1 classid 1:15 htb rate 2mbit ceil 3000kbit #bwhogs tc class add dev vlan60 parent 1:1 classid 1:16 htb rate 20mbit ceil 54000kbit #fullspeed (nfs/email) tc filter add dev vlan60 protocol ip parent 1:0 prio 1 handle 1 fw classid 1:10 tc filter add dev vlan60 protocol ip parent 1:0 prio 1 handle 2 fw classid 1:11 tc filter add dev vlan60 protocol ip parent 1:0 prio 1 handle 3 fw classid 1:12 tc filter add dev vlan60 protocol ip parent 1:0 prio 1 handle 4 fw classid 1:13 tc filter add dev vlan60 protocol ip parent 1:0 prio 1 handle 5 fw classid 1:14 tc filter add dev vlan60 protocol ip parent 1:0 prio 1 handle 6 fw classid 1:15 tc filter add dev vlan60 protocol ip parent 1:0 prio 1 handle 7 fw classid 1:16 ### vlan61 (wireless 54mbit) tc qdisc add dev vlan61 root handle 1:0 htb default 10 tc class add dev vlan61 parent 1:0 classid 1:1 htb rate 54mbit tc class add dev vlan61 parent 1:1 classid 1:10 htb rate 1mbit ceil 12000kbit #dfl tc class add dev vlan61 parent 1:1 classid 1:11 htb rate 1mbit ceil 20000kbit #root tc class add dev vlan61 parent 1:1 classid 1:12 htb rate 1mbit ceil 10000kbit #bwhogs tc class add dev vlan61 parent 1:1 classid 1:13 htb rate 2mbit ceil 3500kbit #dfl tc class add dev vlan61 parent 1:1 classid 1:14 htb rate 2mbit ceil 8000kbit #root tc class add dev vlan61 parent 1:1 classid 1:15 htb rate 2mbit ceil 3000kbit #bwhogs tc class add dev vlan61 parent 1:1 classid 1:16 htb rate 20mbit ceil 54000kbit #fullspeed (nfs/email) tc filter add dev vlan61 protocol ip parent 1:0 prio 1 handle 1 fw classid 1:10 tc filter add dev vlan61 protocol ip parent 1:0 prio 1 handle 2 fw classid 1:11 tc filter add dev vlan61 protocol ip parent 1:0 prio 1 handle 3 fw classid 1:12 tc filter add dev vlan61 protocol ip parent 1:0 prio 1 handle 4 fw classid 1:13 tc filter add dev vlan61 protocol ip parent 1:0 prio 1 handle 5 fw classid 1:14 tc filter add dev vlan61 protocol ip parent 1:0 prio 1 handle 6 fw classid 1:15 tc filter add dev vlan61 protocol ip parent 1:0 prio 1 handle 7 fw classid 1:16
This script is run on startup
Explanation: if a guest is on vlan61 (guest-wireless) then he can use up 12Mbit from eth1 and 3.5Mbit from eth4. In case of congestion he is only guaranteed 1Mbit and 2Mbit
Todo #1: If there are clients on multiple internal networks (eg. eth0 and vlan61) then the shaping is still per-interface and not globally. The only way to fix that is to create a virtual network internally in the Soekris box that can be shaped.
Todo #2: It should be possible to shape all wireless traffic because it shares the same underlying interface (eth6) but tc filters have a bug there (see comment in script)
Todo #3: If a guest on vlan61 downloads via HTTP it is handled by the transparent proxy and the traffic will be shaped according to the eth0->vlan61 rule, which is full-speed. It cannot easily be solved on the soekris box (it lacks knowledge) but it should be possible to do in the proxy (squid has something called "delay pools")
Update: I now implement a fair-use setup
My network supports IPv6. I have previously used site-local addresses but I am currently disabling that because they have been more-or-less deprecated, and since my multiple-ISP connection my sixxs tunnel works very well. For the same reason I have previously used 6to4 tunneling but since it is being phased out (too many problems with misconfigured boxes around the world) then I don't actively use that anymore.
What I have now is a tunnel and subnet from Sixxs. After the tunnel was stable for a few weeks I requested a subnet and got it. I use radvd to give out addresses to client.
$ more /etc/radvd.conf
interface eth0
{
AdvSendAdvert on;
# IgnoreIfMissing on;
MinRtrAdvInterval 3;
MaxRtrAdvInterval 10;
AdvDefaultPreference low;
AdvHomeAgentFlag off;
prefix 2001:16d8:dd31:1::/64
{
AdvOnLink on;
AdvAutonomous on;
AdvRouterAddr off;
AdvPreferredLifetime 120;
AdvValidLifetime 300;
};
};
...
interface vlan60
{
IgnoreIfMissing on;
AdvSendAdvert on;
MinRtrAdvInterval 3;
MaxRtrAdvInterval 120;
AdvHomeAgentFlag off;
prefix 2001:16d8:dd31:3c::/64
{
AdvOnLink on;
AdvAutonomous on;
AdvRouterAddr off;
};
};
When the Sixxs tunnel daemon (aiccu) announces that the tunnel is up then a series of scripts are called:
$ more /etc/aiccu.conf
... setupscript /etc/aiccu_subnets.sh ...
$ more /etc/aiccu_subnets.sh
#!/bin/sh /etc/fix_routes6.sh /etc/assign_sub_addresses.sh 2001:16d8:dd31 #make the rest of the subnet unreachable ip -6 addr add 2001:16d8:dd31::/48 dev lo exit 0
When the aiccu tunnel is up then the IPv6 routes needs to be fixed and the interfaces have to be assigned IPv6 addresses
$ more /etc/fix_routes6.sh
#!/bin/sh ip -6 rule del pref 503 ip -6 rule add from 2002::/16 table 40 priority 503 #Make sure that when we use the sixxs addresses then we route via the sixxs tunnel ip -6 route flush table 60 ip -6 route add table 60 default dev sixxs #ensure that local sixxs addresses are routed correctly ip -6 rule del pref 504 ip -6 rule add from 2001::/16 to 2001:16d8:dd31::/48 table main priority 504 ip -6 rule del pref 505 ip -6 rule add from 2001:16d8:dd00:47::2/64 table 60 priority 505 ip -6 rule del pref 506 ip -6 rule add from 2001:16d8:dd31::/48 table 60 priority 506
$ ip -6 rule show
0: from all lookup local 503: from 2002::/16 lookup force_eth4 504: from 2001::/16 to 2001:16d8:dd31::/48 lookup main 505: from 2001:16d8:dd00:47::2/64 lookup 60 506: from 2001:16d8:dd31::/48 lookup 60 32766: from all lookup main
$ more /etc/assign_sub_addresses.sh
#!/bin/sh
#arguments: interface (eg. eth0)
#output: MAC of the interface. Empty on any error
interface_mac() {
ip link show dev $1 2>/dev/null |fgrep link/ether |awk '{print $2}'
}
#input: mac address (either xxxxxxxxxxxx or xx:xx:xx:xx:xx:xx)
#output: EUI-64 xxxx:xxff:fexx:xxxx
mac_to_eui64() {
local mac=`echo "$1" |tr -d ':'`
local b0=`echo "$mac" | cut -c1-2`
local b1=`echo "$mac" | cut -c3-4`
local b2=`echo "$mac" | cut -c5-6`
local b3=`echo "$mac" | cut -c7-8`
local b4=`echo "$mac" | cut -c9-10`
local b5=`echo "$mac" | cut -c11-12`
b0=$[ $b0 ^ 2 ]
printf "%s%s:%sff:fe%s:%s%s\n" "$b0" "$b1" "$b2" "$b3" "$b4" "$b5"
}
#arguments: interface (eg eth0)
#output: EUI-64 of interface mac
interface_eui64() {
local mac=`interface_mac $1`
mac_to_eui64 "$mac"
}
#Assign ipv6 /64 address to the (sub-)net interface
#arguments: interface prefix "net"
assign_sub_address() {
local eui64=`interface_eui64 $1`
local ipv6address=`printf "%s:%x:%s" "$2" "$3" "$eui64"`
echo "ip addr add $ipv6address/64 dev $1"
ip addr add $ipv6address/64 dev $1
}
#assign ipv6 /64-addresses to the (sub-)net interfaces
#arguments: prefix (must be /48)
assign_sub_addresses() {
assign_sub_address eth0 $1 1
assign_sub_address eth3 $1 4
assign_sub_address eth6 $1 6
assign_sub_address vlan60 $1 60
assign_sub_address vlan61 $1 61
}
if [ $# -ne 1 ]; then
echo "`basename $0`: usage: <prefix>" >&2
echo "prefix must be 48-bit" >&2
exit 99
fi
chunks=`echo "$1" |tr ':' '\n' |wc -l`
if [ $chunks -ne 3 ]; then
echo "`basename $0`: prefix must be exactly in the form xxxx:xxxx:xxxx" >&2
exit 99
fi
assign_sub_addresses $1
Todo #1: Detect when the sixxs tunnel is down and notify radvd to stop announcing those subnets
Todo #2: run DHCPv6 to assign addresses and update entries in dynamic DNS
The ip6tables rules are simpler than the iptables rules because there is no need to DNAT or load-balancing
# Probe modprobe ip6_tables modprobe ip6table_filter # Initialize by flushing all tables ip6tables --flush ip6tables -t mangle --flush # Flush user-defined tables ip6tables --delete-chain ip6tables -t mangle --delete-chain # Set default policy ip6tables --policy INPUT DROP ip6tables --policy OUTPUT ACCEPT ip6tables --policy FORWARD DROP
Otherwise the rules are pretty much like the IPv4 rules. Eg:
ip6tables -A FORWARD -i sixxs -o sixxs -j DROP #dont loop back ip6tables -A FORWARD -i sixxs -o tun6to4 -j DROP #dont forward between the two outsides ip6tables -A FORWARD -i sixxs -j forward_in ip6tables -A FORWARD -i sixxs -j drop_dhcpv6 ip6tables -A FORWARD -i sixxs -o eth6 -j ACCEPT ip6tables -A FORWARD -i sixxs -o vlan60 -j ACCEPT ip6tables -A FORWARD -i sixxs -o vlan61 -j ACCEPT # ip6tables -A FORWARD -i sixxs -p tcp -m state --state ESTABLISHED,RELATED -j ACCEPT ip6tables -A FORWARD -i sixxs -p udp -m state --state ESTABLISHED -j ACCEPT ip6tables -A FORWARD -i sixxs -p icmp6 -m state --state ESTABLISHED,RELATED -j ACCEPT #allow rate-limited ping ip6tables -A FORWARD -i sixxs -o eth0 -p icmp6 --match limit --limit 120/minute -j ACCEPT #allow rate-limited ssh ip6tables -A FORWARD -i sixxs -o eth0 -p tcp --dport 22 -j sshconnect #allow services on webserver/mailserver/ntpserver ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p tcp --dport 80 -j ACCEPT #http ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p udp --dport 53 -j ACCEPT #dns ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p tcp --dport 53 -j ACCEPT #dns ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p udp --dport 5353 -j ACCEPT #dns ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p tcp --dport 5353 -j ACCEPT #dns ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p tcp --dport 4242 -j ACCEPT #scorched earth ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p udp --dport 123 -j ACCEPT #ntp ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p tcp --dport 123 -j ACCEPT #ntp ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p tcp --dport 25 -j ACCEPT #smtp ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p tcp --dport 993 -j ACCEPT #imaps ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p tcp --dport 3868 -j ACCEPT #diameter test server ip6tables -A FORWARD -i sixxs -o eth0 -d 2001:16d8:dd31:1:20d:93ff:fe73:ac12 -p sctp --dport 3868 -j ACCEPT #diameter test server ip6tables -A FORWARD -i sixxs -j REJECT
One major difference from the IPv4 firewall is that all inbound traffic toward the wireless networks are allowed. If a host supports IPv6 then I expect it to have a decent local firewall.
I have too much time