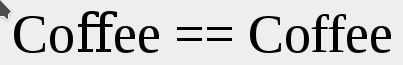
By Ivan Skytte Jørgensen
Copy of blog post I made for Privacore/Findx on 2017-05-05
Are ligatures easy to index for search engines? They mostly are, but correctly identifying and classifying them is not straight-forward.
A digraph is a pair of letters that when combined do not produce the normal sounds of the letters individually. An example is the English "ng" which represents /ŋ/ (velar nasal) as in thing. Another example is the Italian combination of "sc" which corresponds to /ʃ/ (voiceless postalveolar fricative) before -i and -e.
Digraphs are unproblematic for search engines because they can simply be indexed as-is.
It gets more interesting when those letter combination have been used frequently enough that they start to have their use optimized.
When two letters are written as one symbol it is called a ligature. They can be written as one symbol for either stylistic reasons (it looks better) or because they form a completely new letter.
In printing press when using types (metal blocks containing relief of a letter(s)) typesetters optimized common letter combinations. One reason was that it saved time, but another was that they could make the text look better and more readable. An example is the two letters i and j next to each other. Using 2 standard types makes them seem a bit too wide. Using a single type with both letters makes it possible to make it look better.
Some examples of stylistic ligatures:
The function of stylistic ligatures has mostly been taken over by modern typesetting software and their automatic kerning. Kerning, however, does not combine strokes as hand-designed ligatures can do.
The ij ligature is unusual in Dutch because it is considered a single letter officially, but modern Dutch keyboards don’t give access to the letter/ligature. Long discussion at typedrawers.com It seems that decomposing it into the two letters i and j doesn’t change the sound or meaning of Dutch words. So if you search for the movie "Vrijdag" it may have been written with "ij" or "ij". Curious side note: Afrikaans retains the ‘y’ instead of using ‘ij’.
Stylistic ligatures are relatively easy for search engines to deal with – just decompose the ligature into separate letters and index or search that.
Some ligatures are classified as new letters, but the relevant keyboards don’t provide access to them. For example:
I checked with my Hungarian contact and he wasn’t even aware that DZ/Dz/dz (U+01F1..01F3) existed as separate unicode codepoints. So the ligatures may officially be distinct letters but in reality everyone types them as two letters, and decomposing the ligature into d and z doesn’t change the meaning. Something similar is probably going on with Croatian/Bosnian/Serbian/Montenegrin.

Some ligatures are new letters, typically representing a monophthong. They originally started out as two separate letters but became a ligature and eventually no longer considered two separate letters.
Some examples:
Some ligatures have a mixed history and are considered a single letter in some languages and separate letters in others.
One prominent one is Œ/œ. This ligature can be decomposed in English to "oe" or "e" (people rarely write "œconomist" or "amœba") . But in French ("œuvre", "œufs", "bœuf", …) it cannot officially be decomposed. However, back in the DOS age codepage 850 did not have an Œ/œ, so frenchmen lived without it on computers. In more recent time with Unicode support Œ/œ shouldn’t be a problem – except that the main French keyboard layout in ms-windows doesn’t have easy access to it (linux: AltGr+O, mac: Alt+O). So when a word should have "œ" in it it may have been written as "oe" due to technical limitations. Some modern french-aware software knows how to change "oe" into "œ", so the ligature is starting to show up again in electronic formats.
Æ/æ is also language-dependent. In several Nordic languages it is a single letter and cannot be decomposed into "ae" without a change in meaning/pronunciation. In English it is sometimes used in Latin words (eg. "encyclopædia") and can be treated as "ae" (or e).
It is not as simple as you might think. I downloaded the Unicode v10.0 data. it contains detailed information about ~30.000 characters. Some of the ligatures have the word "ligature" in their name, but some don’t. All of the ligatures has a "compatibility decomposition" but many non-ligatures have that too. So I extracted a candidate set, and then made visual inspection of the glyphs in a high-quality font, cross-checked with wikipedia, checked that the decomposition wasn’t a transliteration, and then double-checked with my contacts who knew some of the scripts/languages where the candidate ligatures are used. Conclusion: tricky. And wikipedia is sometimes wrong.