By Ivan Skytte Jørgensen
Copy of blog post I made for Privacore/Findx on 2018-03-16
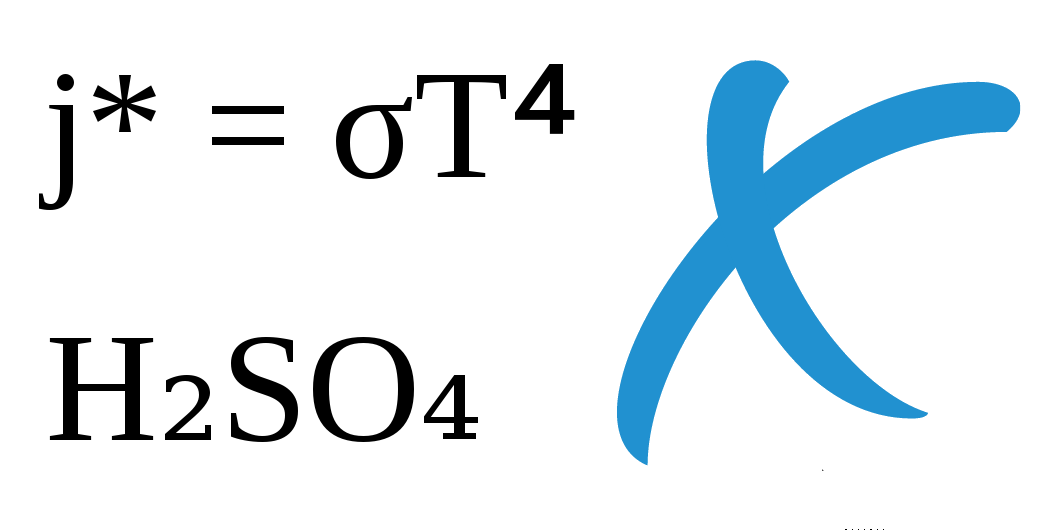
Indexing and searching for H₂O and j*=σT⁴ is not straightforward.
Documents can have superscript and subscript in them as in the above examples. In HTML it can be achieved with the <sub> and <sup> tags, viz.
But superscript/subscript for some characters can also be achieved with dedicated unicode codepoints, eg:
In some fonts the unicode codepoints look slightly different than the result of html tags. The unicode codepoints don’t cover all possibilities but just the ones that are most commonly used in mathematical and chemical formulas. We have seen both methods in the documents that we crawl.
But is H2O equivalent to H(U+2082)O ? We think it is (not implemented yet though).
If a user wants to search for, say, 14 m² of drywall he will typically not enter "m²". And certainly not the html tags. He will typically enter it as:
If he is a computer programmer he might enter it as :
If he is using a clever smartphone it may offer to convert it to "m²" (U+00B2).
In any case, the superscript and subscript are not easy to type, so what users search for may not be how it is written it documents. This is essentially the same problem as the "Škoda problem" I wrote about earlier. Except that it applies to all users – no-one has an easy way to enter superscript-two, even with a space cadet keyboard. (OK, in X11 I can do it with compose-2-s, but I had to look that up).
But the bottom line is that when user searches for "h2o" he may mean "H₂O" and we have to accommodate that.